No doubt you have heard all about the use cases of AI and predictive maintenance. Learn about the algorithms that are actually used to provide analysis and insights based on industrial data sets.
In the previous article (part 1), we discussed the typical architecture of a predictive maintenance system in a manufacturing setting, identifying where the AI-enabled portion of the system is located. We also provide an overview of the Machine Learning Life Cycle, which is a cyclical process that ingests data and employs algorithms to make predictions. In this article, we will take a deep dive into some of the most important AI algorithms employed in predictive maintenance.
Machine Learning Techniques
Machine learning is a branch of artificial intelligence that is revolutionizing many industries. It empowers systems with the ability to learn from data by identifying patterns. When reliable patterns have been identified, machine learning helps systems make decisions autonomously or with minimal human intervention. This makes machine learning an exceptional tool in predictive maintenance.

Figure 1. Machine learning is revolutionizing predictive maintenance.
Machine learning is also a field of study entirely on its own, and new algorithms created in recent years continue to expand this field. For our purpose, we will focus on the machine learning algorithms that are most popular for predictive maintenance applications.
We must first understand that machine learning processes data in two fundamental ways: supervised learning and unsupervised learning. Each one of these approaches serves a distinct purpose; the two primary factors that help you decide which one to choose are the nature of your data and your end goal.
Let’s think about the nature of data in the context of predictive maintenance. All the information you capture about your process (obtained from sensors and other field devices) can possibly be used to train your machine learning model. The main differentiator is going to be whether you have labeled or unlabeled data.
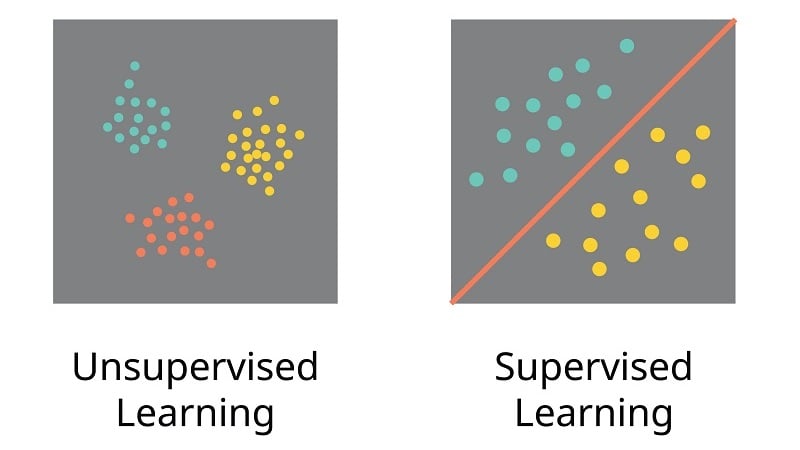
Figure 2. Unsupervised and supervised learning are the two most common approaches to data processing in ML.
Labeled Data for ML
In this context, labeled data translates to data points for which you also know the outcome. Think about past failures with your machine. If you took a snapshot of the process variables at that moment, and that snapshot is identified as a “failure” event, then you have labeled data. For the purpose of training your AI model, you want to use both normal and fail events. The general idea is to teach your model to understand how the inputs tend to look when things are working normally vs. when there are problems.
Unlabeled Data for ML
Data is considered unlabeled when there is no recorded knowledge of the outcome within the dataset. Training a machine learning program with unlabeled data helps you uncover hidden patterns and relationships between variables that are otherwise unknown. Imagine that you want to understand if there is some undetected relationship between machine vibration and quality issues with your finished product. Undoubtedly, your intuition suggests a connection between these two variables, but to what degree?
Knowing the nature of your data is the first decision point that will help you determine which approach to take. Supervised learning works with labeled datasets, while unsupervised learning works with unlabeled datasets. There are additional nuances to consider in this context. Remember, your ultimate goal is the other decision factor; understanding what you are trying to achieve. You can convert labeled data into unlabeled simply by removing the outcome.
If you are trying to make predictions or classifications, then supervised learning is the more appropriate approach. On the other hand, if you are looking for hidden patterns and relationships between variables, then unsupervised learning is a better fit.
Supervised Machine Learning
In predictive maintenance, when you train a machine learning model, you are “feeding it” with historical data. Supervised learning will use labeled historical data to help you make predictions about future outcomes, events, or failures.
One of the most common supervised learning algorithms is Random Forest. It is based on the logic of decision trees. Imagine many decision trees combined and working together to make a prediction. We call it a forest for this reason. Random Forest algorithms work well with large datasets that contain multiple features or variables. It is relatively efficient in computational terms.
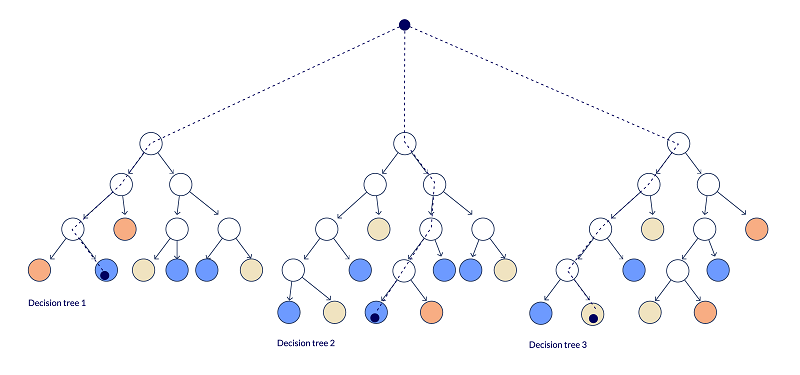
Figure 3. Random Forest makes a prediction based on decision trees.
Another popular supervised learning algorithm is Support Vector Machines (SVM). It is better suited for classification problems. To understand it, imagine you start with an unclassified scatterplot with hundreds or thousands of data points. SVM will process your data and begin to “draw” virtual lines, separating the data points into groups. The number of groups or categories is a parameter you can configure.
One more algorithm, which you have very likely heard about before, is Artificial Neural Networks (ANN). This algorithm is inspired by how the human brain works. Starting from the dataset, it creates a web of interconnected neurons, each one with the ability to make a very specific processing function to the data. ANNs are finding complex and non-linear relationships from within the data and to make intuitive predictions based on that.
Unsupervised Machine Learning
One of the most popular unsupervised learning algorithms in predictive maintenance is K-Means Clustering. This is a classification algorithm that enables you to sort data and group it together into clusters. The classification is primarily based on similarity or distance between data points. The number of clusters identified is a parameter specified in advance. The algorithm will find “K” number of clusters for you, hence its name.
Remember, in unsupervised learning, we don’t have any record of the outcomes of past events. In predictive maintenance, this data is still very useful for anticipating problems. If you consider your clustered data to be within “normal” operating ranges for your process, then any new outlier data point can trigger warnings or faults.
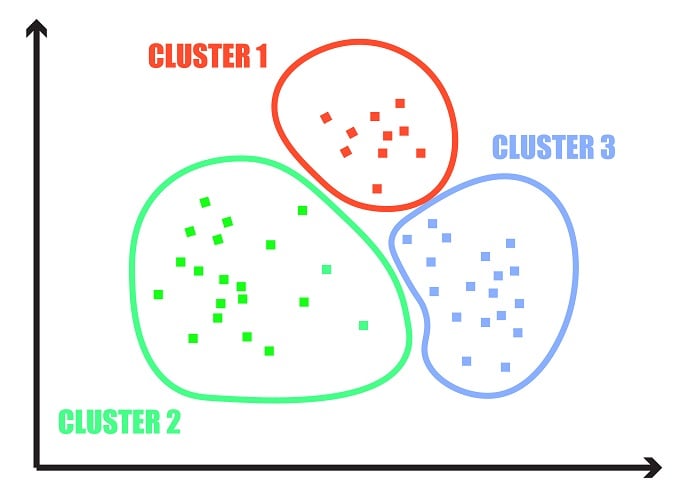
Figure 4. Raw data grouped using K-Means Clustering.
Supervised and unsupervised learning are two essential machine learning techniques largely employed in predictive maintenance. As new algorithms are created and the technology evolves, these techniques will become more crucial in maintenance strategies that must help to drive gains in reliability and sustainability.
Copyright Statement: The content of this website is intended for personal learning purposes only. If it infringes upon your copyright, please contact us for removal. Email: [email protected]